

smb-v1-1.7b is our flagship biological world model. Unlike traditional LLMs that predict tokens, it predicts patient states in latent space, modeling how patients evolve over time and respond to interventions.
Key Differentiators
State Prediction
Predicts future patient states in latent space, not text tokens
Causal Learning
Learns cause-and-effect: (Pre-State + Intervention) → Post-State
Multimodal Fusion
Unifies genomics, imaging, EHR, and proteomics
Environment Activation
Usage
Architecture
The Standard Model uses Joint-Embedding Predictive Architecture (JEPA) — treating the patient as a dynamic “world” and treatments as interventions that change that world.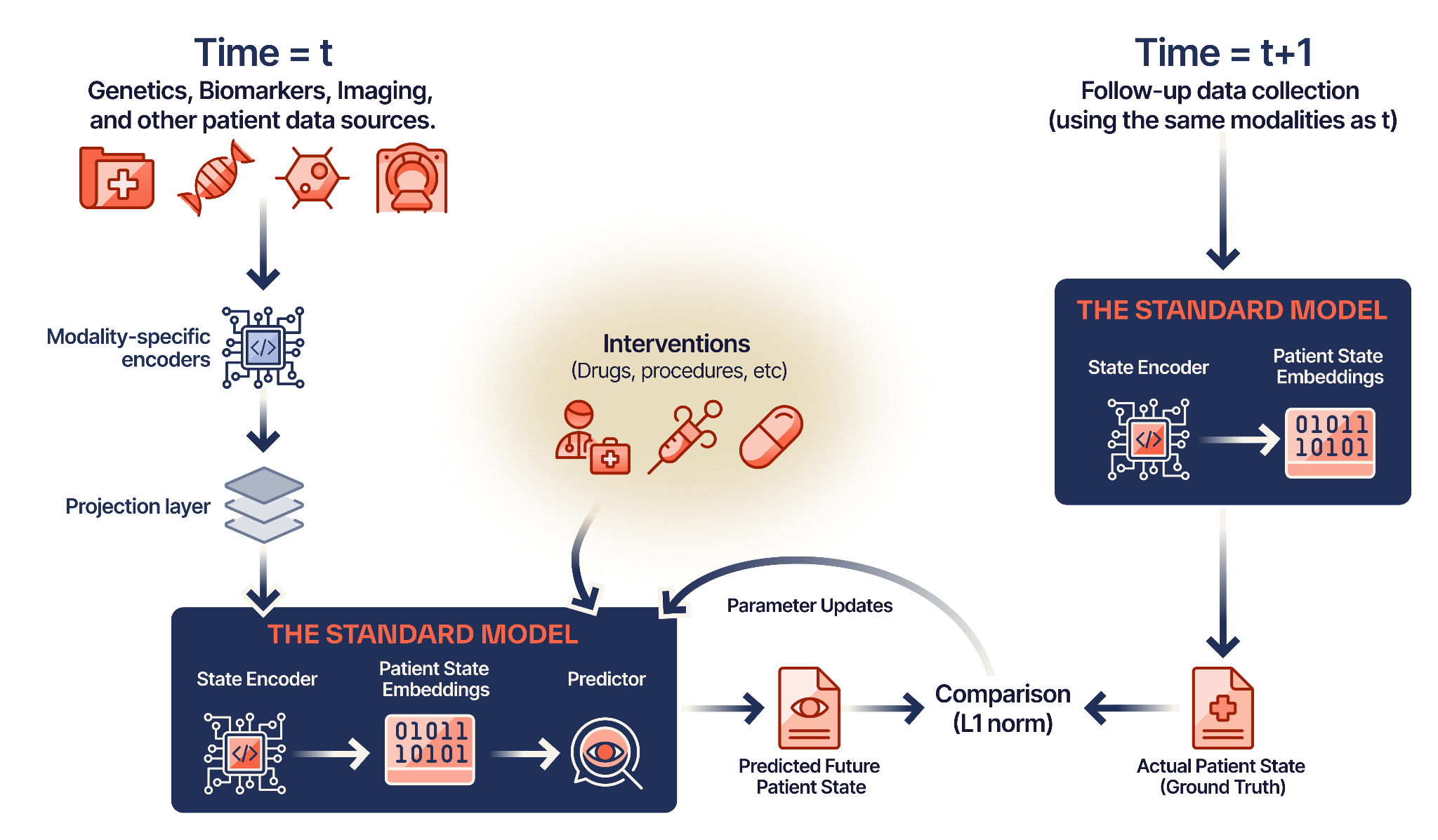
How It Works
Modality Ingestion
Raw signals — genomics, proteomics, imaging, EHR data — pass through modality-specific encoders. Each encoder is trained to extract meaningful representations from its data type.
Fusion Layer
A specialized projector maps these encodings into a universal latent space. This creates a “fused” patient state embedding that retains both high-level semantic context and low-level biological granularity.
State Prediction
Given the current patient state S(t) and an intervention A(t), the model predicts the future state S(t+1) in latent space — not as text, but as a dense embedding.
Extracting Embeddings
Get patient state embeddings for downstream tasks:Use Cases
Treatment Simulation
Simulate how a tumor would evolve under Treatment A versus Treatment B by conditioning on different interventions.
Trajectory Prediction
Predict disease progression over 3, 6, or 12 month windows.
Digital Twins
Create evolving patient representations that update as new data arrives.
Response Prediction
Model probability of response to specific therapies.
Memory Optimization
smb-v1-1.7b requires 16GB GPU memory at full precision. Memory usage can be reduced in several ways:
- Float16
- 8-bit Quantization
- 4-bit Quantization
Hardware Requirements
| Precision | GPU Memory | Recommended GPU |
|---|---|---|
| float32 | 16 GB | A100, A6000 |
| float16 | 8 GB | RTX 4090, A10 |
| 8-bit | 4 GB | RTX 3080, T4 |
| 4-bit | 2 GB | RTX 3060 |